

Building a Stock System That Cannot Be Wrong
How event-sourced ledger architecture eliminated stock discrepancies in our optical retail app
Hi there 👋
I'm an Indonesian who loves coffee and dogs!! Also, code sometimes.
Currently studying at Kyoto College of Graduate Studies for Informatics. 🏫
Work as Full-Stack Engineer
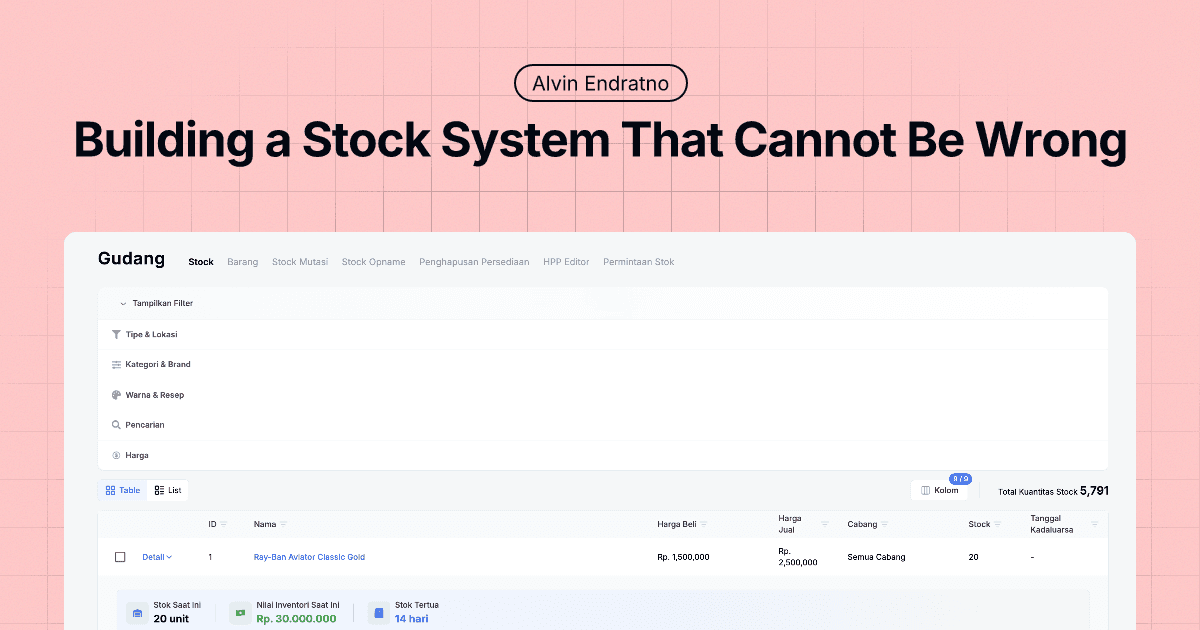
The Problem Every Retailer Knows
If you've ever managed inventory for a retail business, you know the nightmare: the system says you have 5 units, but you can only find 3 on the shelf. Or worse, you sell something the system said was in stock, only to discover it was already gone.
Traditional inventory systems store stock as a single number in a database column — and every operation just increments or decrements that number. It works... until it doesn't. A failed API call, a race condition, a developer forgetting to update the count in one edge case — and suddenly your stock is off. Forever. And you have no idea when or why it went wrong.
I built Lensiro's stock system so that this class of bugs is architecturally impossible.
The Core Idea: Never Store the Stock Count
Here's the fundamental insight: the stock quantity is never stored anywhere. There is no quantity column in the Stock table. Zero. None.
Instead, every time anyone asks "how many of item X do we have at branch Y?", the system calculates it from scratch by summing up every movement that has ever happened to that item.
Stock = SUM(all inflows) - SUM(all outflows)
That's it. That's the whole trick.

The Ledger: Every Movement Tells a Story
Every stock change is recorded as an immutable event in its own dedicated table. There are 8 types of movements:
Things that add stock (+):
Purchase Receive — goods physically received from a supplier
Stock Opname (positive) — physical count reveals more stock than expected
Transfer In — items arriving from another branch
Things that remove stock (-):
Sale — items sold to customers
Complimentary — items given away
Purchase Return — items sent back to supplier
Transfer Out — items shipped to another branch
Stock Opname (negative) — physical count reveals less stock than expected

Each movement record contains:
The count (how many)
The timestamp (when)
The cost price (for accounting)
A link back to its source document (the sale, the purchase order, the transfer)
These records are append-only. Once a purchase receive is recorded, it stays recorded. You don't go back and edit the number — if there's a correction, you create a new adjustment record. The history is sacred.
This Was Not Easy to Implement
The idea is simple — just sum up all movements. The implementation? Not so much. Here's what made it hard and what I did to make it work.
The Query From Hell
The stock count query unions 9 different tables into a single CTE (Common Table Expression). Each sub-query has its own JOIN conditions, its own sign logic (positive for inflows, negative for outflows), and its own edge cases. The first version of this query was slow. Really slow. Loading the stock list page with a few thousand items could take seconds.
The fix was pre-aggregating inside each UNION ALL branch. Instead of dumping every individual row into the CTE and then aggregating at the end, each sub-query does its own GROUP BY stockId and SUM(count) first. This means the CTE combines 9 small, pre-summed result sets instead of potentially tens of thousands of raw rows. The difference was night and day.
I also split the query into layers using multiple CTEs:
movements— unions and pre-aggregates all 9 movement sourcesfiltered_stock— applies all the filter conditions (branch, category, brand, color, prescription, price range, name search) against the Stock and Item tablesstock_counts— joins filtered stocks with their movements, applies HAVING clauses for min/max stock filters
This way the database can optimize each layer independently. Filters narrow down which stocks we care about before we join with movements, so we're not calculating counts for items nobody asked for.
The Consistency Problem
If you're not careful, event-sourced stock calculation can show inconsistent numbers. Imagine:
The stock list page calculates stock using the SQL CTE on the server
A user clicks "Detail" on an item, which fetches all relations and calculates stock using TypeScript on the client (
calcStockPlus()minuscalcStockMinus())If the logic in SQL and TypeScript doesn't match exactly, the numbers disagree
This actually happened during development. I added a new movement type (StockBuffer) to the SQL query but forgot to add it to the TypeScript calculation. The stock list showed one number, the detail view showed another. Staff would understandably lose trust in the system.
The solution was discipline: every time a new movement type is added, it must be added in three places — the SQL CTE, the TypeScript calcStock functions, and the generateTrail function that renders the timeline. There's no clever abstraction that enforces this automatically. It's just a rule you follow.
FIFO Cost Price Calculation
Getting the stock count right was only half the battle. For accounting, every outflow (sale, return, transfer) needs a cost price — how much did we pay for this specific unit? We use FIFO (First In, First Out): the oldest purchased units are assumed to be sold first.
The tricky part: what happens when you sell an item before the purchase is recorded? This happens in real retail — you receive goods on Monday, sell one on Tuesday, but the purchase order isn't entered until Wednesday. The outflow happened before the inflow exists in the system.
I handle this with retroactive cost pricing. Outflows that happen before sufficient inflows are queued as "pending." When a new purchase is recorded, the system re-processes pending movements and assigns them the correct cost price. This runs asynchronously using waitUntil() after the main transaction commits, so it doesn't block the user.
Batch Operations
Early on, creating stock records one at a time during bulk operations (like receiving a purchase order with 50 line items) was painfully slow — each one triggered a separate findFirst then create query. I replaced this with fetchOrCreateStocksBatch(), which finds all existing stocks in one query, identifies the missing ones, bulk-creates them with createMany, and fetches the new ones. What used to be 100+ queries became 3-4.
Why "Cannot Be Wrong"?
When I say this system "cannot be wrong," I mean something very specific. The stock count is mathematically derived from the complete set of transactions. If the transactions are recorded correctly, the stock count is correct — by definition. There is no way for the count to "drift" out of sync, because there is no separate count to drift.
Here's what makes this different from a traditional UPDATE stock SET quantity = quantity - 1 approach:
1. No Stale State
There is no cached or stored quantity that can go stale. Every query recalculates from the source of truth. If you run the query right now and again in 5 minutes (with no new transactions), you get the exact same answer.
2. Complete Auditability
Every single unit of stock can be traced back to how it got there. Got 12 units? You can see: 10 came from a purchase on January 3rd, 3 came from a transfer on January 15th, and 1 was sold on January 20th. 10 + 3 - 1 = 12. The math is right there on screen.

3. Self-Correcting with Stock Opname
When staff does a physical stock take (we call it "Stock Opname"), they count what's actually on the shelf and enter it. The system compares: ledger says 12, physical count says 11. It creates an adjustment record of -1. Now the ledger says 11. The discrepancy is recorded as an event itself — not silently patched.

4. Atomic Transactions
Every operation that touches stock is wrapped in a database transaction. If you're recording a sale with 3 line items, either all 3 items get their movement records, or none of them do. No partial states.
5. Branch Isolation
Each branch has its own stock ledger. Branch A's inventory is completely independent of Branch B's. When items move between branches, it creates a pair of records: a decrease at the source branch and an increase at the destination branch (only when the receiving branch confirms receipt).

The SQL Behind It
On the backend, a single SQL query with a Common Table Expression (CTE) unions all movement tables together and sums them up:
WITH movements AS (
SELECT stockId, SUM(count) as value
FROM PurchaseReceiveItem
GROUP BY stockId
UNION ALL
SELECT stockId, SUM(count) as value
FROM StockAdjustment
GROUP BY stockId
UNION ALL
SELECT targetStockId, SUM(count) as value
FROM StockMutationItem
WHERE received = true
GROUP BY targetStockId
UNION ALL
SELECT stockId, -SUM(count) as value
FROM SaleItem
GROUP BY stockId
-- ... and so on for all movement types
)
SELECT stockId, COALESCE(SUM(value), 0) AS stockCount
FROM movements
GROUP BY stockId
On the client side, the same logic is mirrored in TypeScript — calcStockPlus() sums all inflows, calcStockMinus() sums all outflows, and calcStock() returns the difference. Both server and client use the same formula. There's nowhere for the numbers to disagree.
The Trail View: Show Your Work
My favorite part of this system is the trail view. When a staff member clicks on any stock item, they see a full chronological timeline of every movement, each one clickable back to the source document.
It's like a bank statement for inventory. Every "deposit" and "withdrawal" is listed. The running total is visible. Anyone can verify the math by scrolling through the list.
This isn't just for debugging — it's a daily tool. When a staff member questions the count, they don't need to call IT. They click "Detail," read the trail, and understand exactly why the system says what it says.
But Wait — It Can Still Be Bugged
I want to be honest here. When I say the system "cannot be wrong," I'm talking about the architecture — the structural impossibility of stock count drift. The system is designed so that if all movements are recorded, the count is mathematically guaranteed to be correct.
But software is software. Bugs can still happen:
A movement could fail to be recorded. If a purchase receive action crashes halfway through and the transaction doesn't roll back properly, a movement might be lost. The stock count would then be wrong — not because of drift, but because of missing data.
A movement could be recorded with the wrong count. If the UI sends
count: 10instead ofcount: 1due to a frontend bug, the ledger faithfully records the wrong number. Garbage in, garbage out.A new movement type could be added without updating the calculation. If a developer adds a 9th movement type but forgets to include it in the calculation functions or the SQL query, those movements would be invisible.
Concurrent transactions could interact unexpectedly. Although we use database transactions, extremely high concurrency on the same stock item could theoretically cause issues depending on the isolation level.
The client and server calculations could diverge. We mirror the logic in both SQL and TypeScript. If someone updates one but not the other, you'd see different numbers depending on where you look.
The architecture eliminates the most common class of inventory bugs — the silent drift that accumulates over months and is impossible to diagnose. But it doesn't make the software immune to all bugs. No architecture can.
What it does give you is debuggability. When something looks wrong, you can open the trail, read every movement, and find the problem. Compare that to a traditional system where the stock is just... a number. How did it get there? Who knows.
The Buffer System: Handling In-Progress Sales
One more detail I'm proud of. In optical retail, there's often a gap between selling an item and physically handing it to the customer (because lenses need to be fitted into frames). During this gap, the item is "sold" but still physically in the store.
We handle this with a buffer concept. The stock count includes sold-but-unfulfilled items as decreases, but the UI shows a clear breakdown:
Total Stock: 5 (the ledger total)
Buffer: 2 (sold but not yet fulfilled)
Available: 3 (actually available to sell)

This prevents double-selling without hiding information from staff.
Lessons Learned
Derived state > stored state. If you can calculate it, don't store it. Stored state lies. Calculated state can't.
Make the audit trail a feature, not an afterthought. When staff can see why the number is what it is, trust in the system goes up dramatically.
Event sourcing isn't just for distributed systems. Even a simple retail app benefits from treating every state change as an immutable event.
The best debugging tool is transparency. When something goes wrong, a complete trail of events is worth more than any amount of logging.

About Lensiro
Lensiro is a complete retail management platform built specifically for optical stores. It handles everything an eyewear business needs in one place — from inventory and stock management across multiple branches, to point-of-sale, purchasing, member management, and accounting with double-entry bookkeeping. If you run an optical retail business and want a system that actually gets inventory right, check it out at lensiro.com.
Built with Next.js, PostgreSQL, Prisma, and a lot of stubbornness about doing inventory right.


