Scrape and Extract Information from Images with GCP's AutoML Vision
This article will introduce a way to extract pieces of information from images by utilizing one of Google Cloud Platform's services, the AutoML Vision

Hi there 👋
I'm an Indonesian who loves coffee and dogs!! Also, code sometimes.
Currently studying at Kyoto College of Graduate Studies for Informatics. 🏫
Work as Full-Stack Engineer
Nowadays, much information is stored in the form of images. That is also true on websites. The problem with that it is more challenging for computers to recognize the information and scrape it. This article will introduce a way to extract pieces of information from images by utilizing one of Google Cloud Platform's services, the AutoML Vision.
About Web Scraping
Web scraping has been developing in past years. We also have tools that don't require coding to scrape (ParseHub, Octoparse). While it is easy, it lacks flexibility.
Building our scraper from zero allows us to use it however we want. For Python, Scraping can be done using scraping libraries (Requests, BeautifulSoup, Cheerio) and frameworks like Scrapy and Selenium.
In this experiment, we will use BeautifulSoup to parse HTML documents to find the part we want. GCP's AutoML will also be used to extract text from images.
Overview Process
Before we go hands-on with implementation, I want to explain how it will work from accessing the web page until we get the pieces of information that we want.
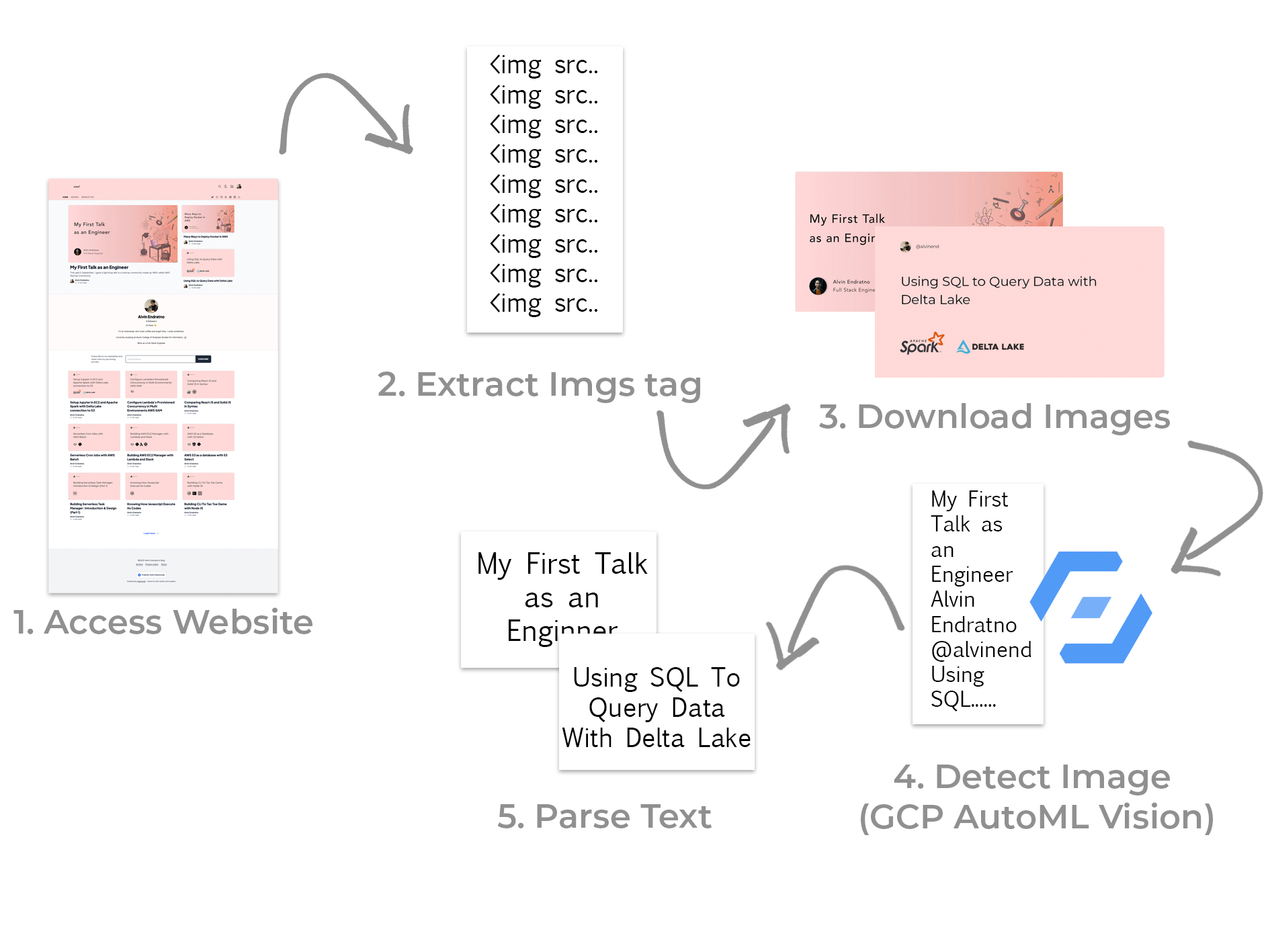
First, we need to access a web page from which the image we want to extract. In this article, we will use my blog page for privacy reasons, and I want to avoid getting in trouble for scraping another website and publishing an article about it. We aim to get all titles from the article's cover images I post.
After we got the HTML document of the web page, we extracted the image by finding the "img" tag. We should have a list of "img" tags before we move to the next step.
From that "img" tags list we download images by extracting URL from "src" attribute. Download, as binary and store it as variable.
Next, we send a request containing the binary of that images to GCP's Auto ML Vision. There is a free tier on it, don't worry about spending money on this experiment.
The response from AutoML Vision will be a string, but it could be more pretty. We need to make those strings readable and useable for the final part.
Implement
Now that you have a high level of what we will build, let us start coding!
First thing first, we will need to set up the environment. I use venv to keep my computer clean, but it is up to you. There are many ways to do this that I will not explain. Make sure to install packages. Below are the packages that we need.
from io import BytesIO
from bs4 import BeautifulSoup as bs
from google.cloud import vision
import urllib
import re
import requests
Our first method will be to get an HTML document from a URL (my blog page) and extract "img" tags from it. After that, we used links from the "src" attribute, downloaded them, and stored them in a variable. The return value is a list of image files in binaries.
def get_image_files_from_link(url):
r = requests.get(url)
soup = bs(r.content)
image_tags = soup.find_all(
'img', {'src': re.compile('(.*)(jpg|png|gif|JPG|PNG|GIF)')})
image_srcs = list(map(lambda x: x.attrs.get('src'), image_tags))
image_files = []
for src in image_srcs:
try:
src = src.split('=')[1]
src = urllib.parse.unquote(src)
response = requests.get(src)
image_files.append(BytesIO(response.content))
except Exception as e:
continue
return image_files
Using the first method's return value, we create a method to loop it and detect (as in extracting text from an image) and print it. We will implement the "detect" method in a moment.
def get_text_from_image(url):
image_files = get_image_files_from_link(url)
titles = []
for image_file in image_files:
title = detect(image_file)
title = parse_text(title)
if title != '':
titles.append(title)
print(titles)
For the "detect" method, we initialize GCP's client, build a request, and send it to GCP. The response will be an object with metadata on how it was processed, but the text_annotations content is essential. It has extracted text from an image.
def detect(image_file):
try:
client = vision.ImageAnnotatorClient()
content = image_file.read()
image = vision.Image(content=content)
response = client.document_text_detection(image=image)
labels = response.text_annotations
# Get longest text in labels.description
text = ''
for label in labels:
if len(label.description) > len(text):
text = label.description
return text
except Exception:
return ''
If we return it as it is, we will receive a string with many unnecessary values like space, line breaks, or words we don't want. Here is the example of it.
['aend', 'aend', 'My First Talk\nas an Engineer\nAlvin Endratno\nFull Stack Engineer\nZel', '', 'Many Ways to\nDeploy Docker in\nAWS\nAlvin Endratno\nFull Stack Engineer\nZel', '', '@alvinend\nUsing SQL to Query Data with\nDelta Lake\nAPACHE\nSpark A\nDELTA LAKE', '', '', '@alvinend\nSetup Jupyter in EC2 and\nApache Spark with Delta Lake\nconnection to S3\nAPACHE\nADELTA LAKE', "@alvinend\nConfigure Lambda's Provisioned\nConcurrency in Multi Environments\nAWS SAM\naws", '@alvinend\nComparing React JS and\nSolid JS in Syntax', '@alvinend\nServerless Cron Jobs with\nAWS Batch\naws', '@alvinend\nBuilding AWS EC2 Manager with\nLambda and Slack\naws\n●入米', '@alvinend\nAWS S3 as a Database\nwith S3 Select\naws\n2', '@alvinend\nBuilding Serverless Task Manager:\nIntroduction & Design (Part 1)\nXd', '@alvinend\nKnowing How Javascript\nExecute Its Codes\nUS', '@alvinend\nBuilding CLI Tic Tac Toe Game\nwith Node JS\nUS\nXXO\nOox\nXXX']
To avoid that, we need to parse it. Usually, it is done by writing a Regular Expression (REGEX) or some machine learning, but in this example, we will remove a word that has at least five characters, remove the author's name and trim it.
def parse_text(text):
parsed_text = ''
for c in text.split('\n'):
if len(c) < 5:
continue
parsed_text += c + ' '
parsed_text = parsed_text.replace('@alvinend', '')
parsed_text = parsed_text.replace('Alvin Endratno', '')
parsed_text = parsed_text.replace('Full Stack Engineer', '')
parsed_text = parsed_text.strip()
return parsed_text
The last thing to do is run it. python3 main.py
if __name__ == '__main__':
res = get_text_from_image(
'https://blog.alvinend.tech/')
And the result is below.
['My First Talk as an Engineer', 'Many Ways to Deploy Docker in', 'Using SQL to Query Data with Delta Lake APACHE Spark A DELTA LAKE', 'Setup Jupyter in EC2 and Apache Spark with Delta Lake connection to S3 APACHE ADELTA LAKE', "Configure Lambda's Provisioned Concurrency in Multi Environments AWS SAM", 'Comparing React JS and Solid JS in Syntax', 'Serverless Cron Jobs with AWS Batch', 'Building AWS EC2 Manager with Lambda and Slack', 'AWS S3 as a Database with S3 Select', 'Building Serverless Task Manager: Introduction & Design (Part 1)', 'Knowing How Javascript Execute Its Codes', 'Building CLI Tic Tac Toe Game with Node JS']
It could be better, but it shows how to extract information from images with GCP AutoML Vision.
Closing
In real-life projects, we usually extract information from images to get information unavailable in texts on websites. For example, a company website with a phone number in an image. We can get it by using a regex that determines the phone number in the raw string GCP AutoML provided.
Also, it is crucial to ensure it is legal before scaping websites. Happy Scraping!