Setup Jupyter in EC2 and Apache Spark with Delta Lake connection to S3
This time we will be building an EC2 server with Apache Spark with Delta Lake on it and accessible using Jupyter from your local computer.

Hi there 👋
I'm an Indonesian who loves coffee and dogs!! Also, code sometimes.
Currently studying at Kyoto College of Graduate Studies for Informatics. 🏫
Work as Full-Stack Engineer
Delta lake has been booming for the last two years after Databricks announce it as "New Generation Data Lakehouse," but behind the boom, there are not enough examples and posts of it. I want to change it by adding one article about it. This time we will be building an EC2 server with Apache Spark with Delta Lake on it and accessible using Jupyter from your local computer.
Launching EC2
We will not do an EC2 launch tutorial, so I am just going to write simple steps and hope you can manage! (Tips: There are a lot of tutorials about EC2, google it)
- Log in to your AWS Console
- Launch EC2 with these setting
| Name | Value |
| OS | Ubuntu 22.04 64bit |
| Instance type | t3a.xlarge |
| Key Pair | (Fill it with your key) |
| Security Group | Open All Trafic to Public |
| Storage | gp2 80GB |
That is all! Try to ssh into EC2 before continuing to the next step.
Install Required Tools
Next, let's install python, pip, and pyspark
Install Python
Ubuntu 22.04 LTS ships with the latest toolchains for Python, Rust, Ruby, Go, PHP and Perl, and users get first access to the latest updates for essential libraries and packages. Just in case, let's upgrade packages.
sudo apt update
sudo apt -y upgrade
And check out the python version.
python3 -V
When I wrote this article, my latest python version was 3.10.4.
Install PIP
Although our python is built-in into Ubuntu, it does not come with package manager pip. So let us install it!
sudo apt install -y python3-pip
Same with python, it is always good to check if it is correctly installed or not. Run the below command to check its version.
pip -V
Here is my output.
pip 22.0.2 from /usr/lib/python3/dist-packages/pip (python 3.10)
Install Apache Spark
Running Delta Lake require Apache Spark, so let's install it!
pip install pyspark==3.3
Install Java
Execute the following command to install the JRE and JDK from OpenJDK 11.
sudo apt install default-jre
sudo apt install default-jdk
It is always good to check if it is correctly installed or not. Run the below command to check its version.
java -version
Here is my output.
openjdk version "11.0.16" 2022-07-19
OpenJDK Runtime Environment (build 11.0.16+8-post-Ubuntu-0ubuntu122.04)
OpenJDK 64-Bit Server VM (build 11.0.16+8-post-Ubuntu-0ubuntu122.04, mixed mode, sharing)
Setting up Jupyter
Running your Delta Lake in CLI is cool, but it isn't enjoyable. So, let us install Jupyter in Ubuntu which is accessible from our local computer.
Install Jupyter
Believe it or not, to run jupyter, we need to install jupyter. Here is a command to install it.
pip install notebook
Easy right? But in my case, I had some problems. Although it was installed successfully, I can't run the jupyter command. When I look back at the install log, I found some warnings.
WARNING: The script jupyter-execute is installed in '/home/ubuntu/.local/bin', which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
So I suspect it will work when I add that directory to the path. For adding a path to ~/.bashrc, run the command below.
echo "export PATH=$PATH:$HOME/.local/bin" | tee -a ~/.bashrc
And I successfully ran jupyter in my terminal.
Expose Jupyter to Public
The next step is to make jupyter accessible from our local computer. First, generate jupyter's config file by executing the command below.
jupyter notebook --generate-config
It should output your config directory. Mine was /home/ubuntu/.jupyter/jupyter_notebook_config.py. Open that file.
vi /home/ubuntu/.jupyter/jupyter_notebook_config.py
Find, Un-comment, and edit these options to expose your juypter
First one is c.Notebook.App.ip. It is to specify the IP address the notebook server will listen on so that we can access it with our EC2 public IP address.
c.NotebookApp.ip = '*'
Second is c.NotebookApp.open_browser and specify it to False. We don't want our Ubuntu to open the notebook when we start the server
c.NotebookApp.open_browser = False
And we are all set. The last thing to do is to start the notebook server.
jupyter notebook
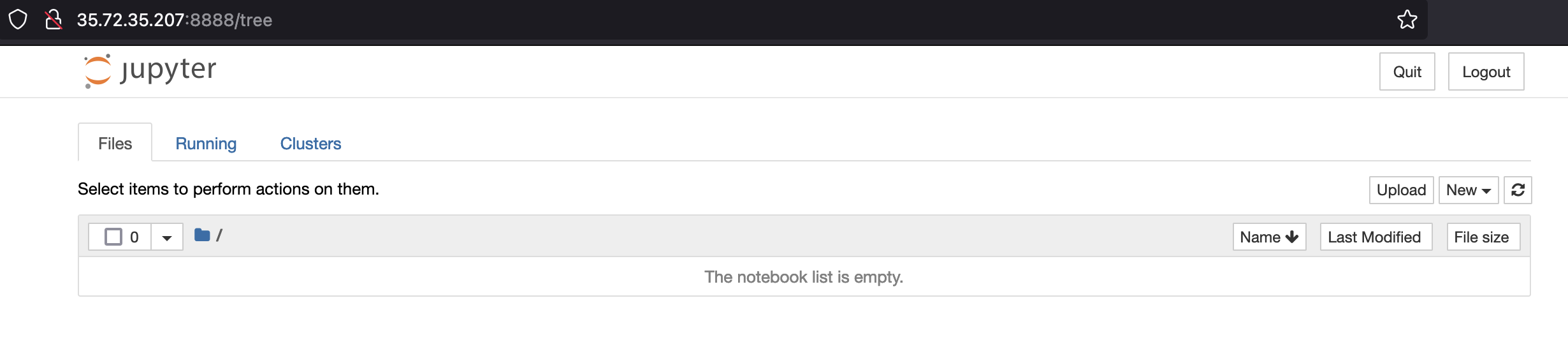
Access it with EC2's public IP, and we should get a notebook similar to this.
Run Spark with Delta Lake
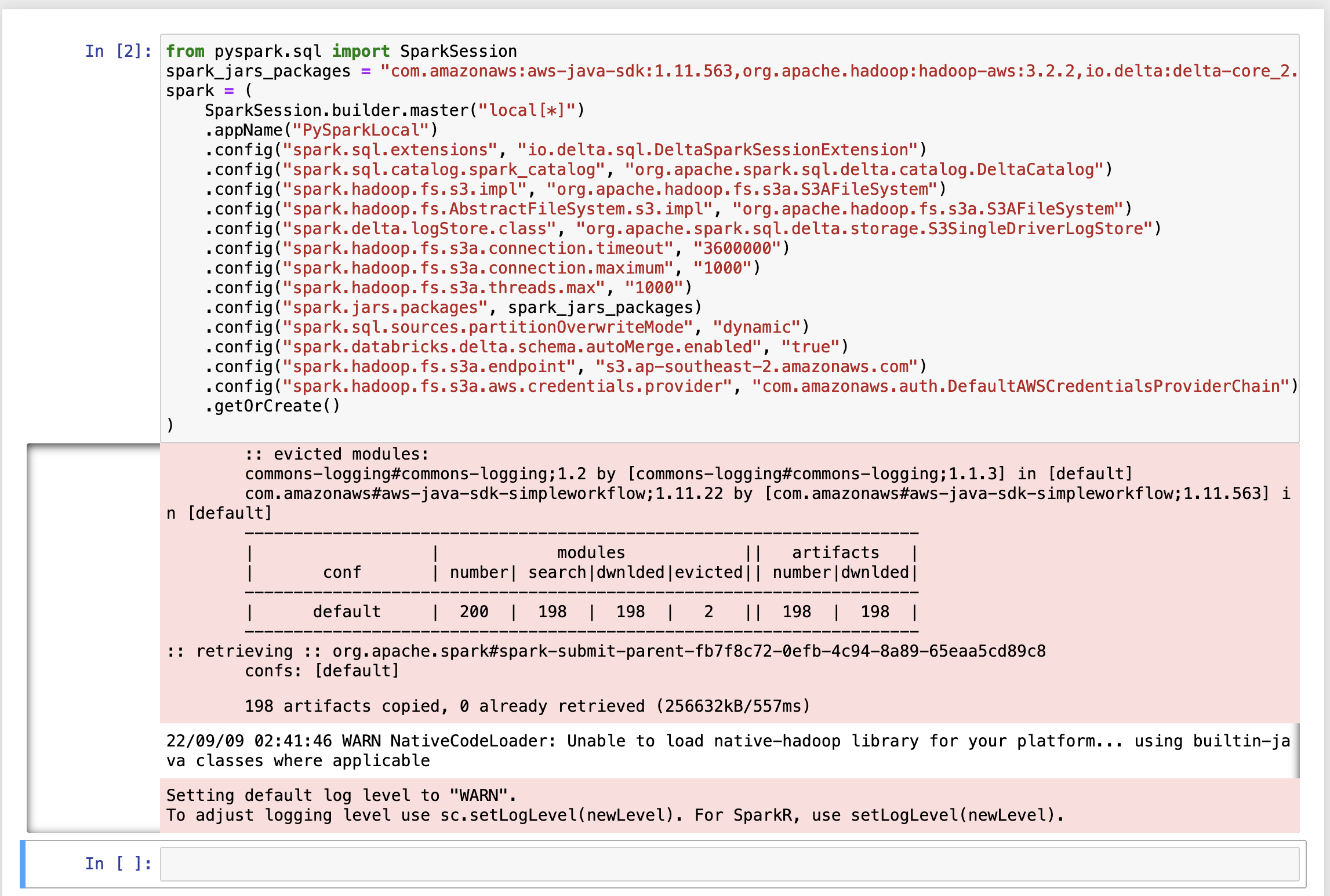
In the final step, let us initiate spark's session and confirm if there are no errors. To do that, we need to create a new notebook in jupyter's console and run the code below. (It is set up to connect with S3)
Note: I tried many ways to make this work, including setting it with the latest version of delta lake and Hadoop (3.3.x), but it throws a java error, and I cannot find a way to fix it. If you can have the latest version working, please let me know in the comments. I referenced the below code from Getting started with Delta Lake & Spark in AWS— The Easy Way post by Irfan Elahi (Thank you!).
from pyspark.sql import SparkSession
spark_jars_packages = "com.amazonaws:aws-java-sdk:1.11.563,org.apache.hadoop:hadoop-aws:3.2.2,io.delta:delta-core_2.12:1.2.1"
spark = (
SparkSession.builder.master("local[*]")
.appName("PySparkLocal")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.config("spark.hadoop.fs.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
.config("spark.hadoop.fs.AbstractFileSystem.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
.config("spark.delta.logStore.class", "org.apache.spark.sql.delta.storage.S3SingleDriverLogStore")
.config("spark.hadoop.fs.s3a.connection.timeout", "3600000")
.config("spark.hadoop.fs.s3a.connection.maximum", "1000")
.config("spark.hadoop.fs.s3a.threads.max", "1000")
.config("spark.jars.packages", spark_jars_packages)
.config("spark.sql.sources.partitionOverwriteMode", "dynamic")
.config("spark.databricks.delta.schema.autoMerge.enabled", "true")
.config("spark.hadoop.fs.s3a.endpoint", "s3.ap-southeast-2.amazonaws.com")
.config("spark.hadoop.fs.s3a.aws.credentials.provider", "com.amazonaws.auth.DefaultAWSCredentialsProviderChain")
.getOrCreate()
)
And it should install the necessary packages and if there are no errors, congratulations you set up Apache Spark, Delta Lake, and Jupyter in EC2.
Closing
When using Delta Lake for lakehouse in companies, we usually use databricks service, AWS EMR, or services that use for big data processing not traditional servers, maybe that is why there are only a few articles or tutorials that provide a way to deploy it in servers like EC2. Next, I will be performing Delta Lake process in this notebook. Hope this helps you, Cheers!