Using SQL to Query Data with Delta Lake
We can use Delta Lake to import and query data with our beloved SQL.

Hi there 👋
I'm an Indonesian who loves coffee and dogs!! Also, code sometimes.
Currently studying at Kyoto College of Graduate Studies for Informatics. 🏫
Work as Full-Stack Engineer
Last time, we set up Jupyter in EC2 and Apache Spark with Delta Lake connection to S3. We will import data from the dataset and query it with SQL this time.
About Dataset
For this experiment, we will use a dataset about courses, students, and their interactions with Virtual Learning Environment (VLE) for seven selected courses (called modules). You can get it here.
It has enormous data. One of them has around 450 MB of CSV. We will use that to see how fast Delta Lake can insert and query the data.
Import Dataset
After we downloaded the dataset and uploaded it into the server from jupyter, we needed to read it with Apache Spark, write it as delta's parquet, and upload it to S3.
Below is a method to do that.
def import_csv(filename):
# Read CSV from local directory
df = spark \
.read \
.option("header","true") \
.csv(f"./dataset/{filename}.csv")
# Write to S3
df.write\
.mode("overwrite")\
.format("delta")\
.save(f"s3://s3-bucket-name/table/{filename}/")
After that, call it with a parameter of the name of the CSV name. Below is an example of importing assessment.csv to delta's parquet in S3.
import_csv("vle")
After it succeeds, we can confirm it by going to S3.
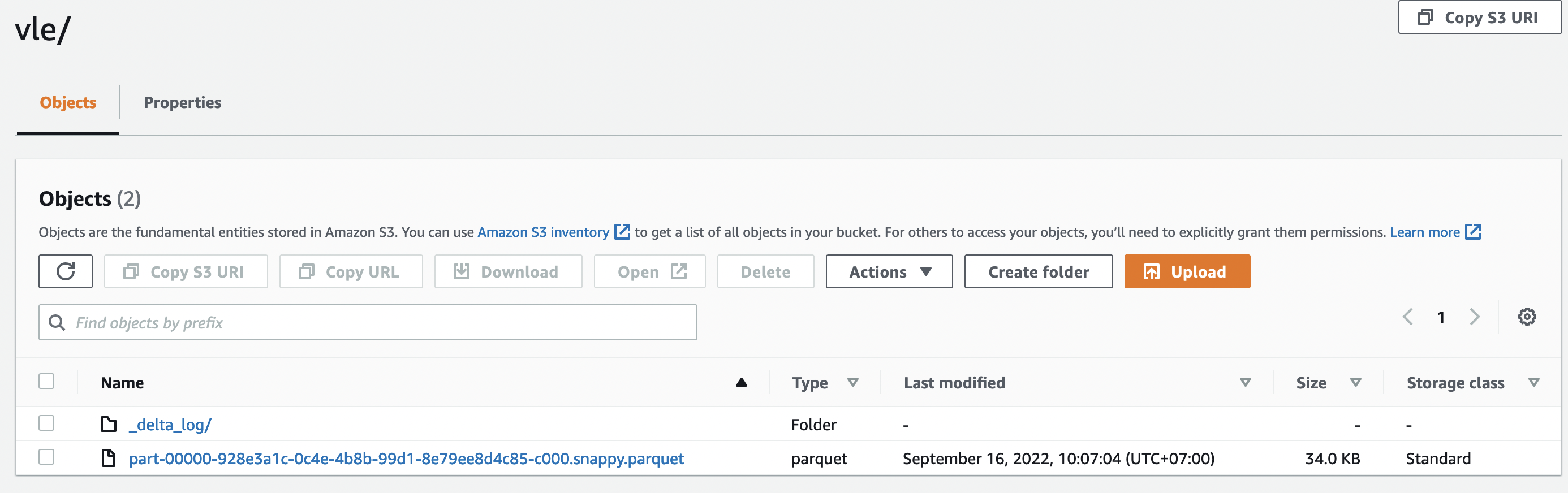
Repeat it so that all CSV can be imported. Here is a summary of the file name and execution time.
| File Name | Size | Execution Time |
| assessments.csv | 8 kB | CPU times: user 8.07 ms, sys: 1.11 ms, total: 9.19 ms Wall time: 3.59 s |
| courses.csv | 526 B | CPU times: user 18.2 ms, sys: 5.43 ms, total: 23.6 ms Wall time: 4.62 s |
| studentAssessment.csv | 5.69 MB | CPU times: user 14.4 ms, sys: 5.06 ms, total: 19.5 ms Wall time: 7.12 s |
| studentInfo.csv | 3.46 MB | CPU times: user 10.7 ms, sys: 9.68 ms, total: 20.4 ms Wall time: 5.93 s |
| studentRegistration.csv | 1.13 MB | CPU times: user 11.9 ms, sys: 0 ns, total: 11.9 ms Wall time: 4.96 s |
| studentVle.csv | 454 MB | CPU times: user 15 ms, sys: 5.31 ms, total: 20.3 ms Wall time: 27.5 s |
| vle.csv | 271 kB | CPU times: user 11.9 ms, sys: 0 ns, total: 11.9 ms Wall time: 3.63 s |
Querying Data
After we import all our datasets into S3, we can start querying them with SQL. Before that, let me declare one method that I will explain later.
def table_dir(tablename, with_as=True):
if with_as:
return f"delta.`s3://s3-bucket-name/table/{tablename}/` AS {tablename}"
else:
return f"delta.`s3://s3-bucket-name/table/{tablename}/`"
When querying with delta lake, we need to specify where the folder that holds delta's parquet is. Rather than writing it every time, I made a method of it.
SELECT
Start with an easy one. Let us write a SELECT query.
spark.sql(f"""
SELECT code_module, count(*) as module_count
FROM {table_dir('studentVle')}
GROUP BY code_module
""").show()
Here we query a 400MB table and group it. It only took 1.74 seconds!

JOIN
Let's take it a little further. Try joining three tables.
spark.sql(f"""
SELECT activity_type, SUM(sum_click)
FROM {table_dir('studentVle')}
INNER JOIN {table_dir('vle')}
ON studentVle.id_site = vle.id_site
INNER JOIN {table_dir('studentInfo')}
ON studentVle.id_student = studentInfo.id_student
WHERE studentInfo.final_result = "Pass"
GROUP BY vle.activity_type
""").show()
Here we got two joins, one where and one grouping. Execute time is a little longer at 6.88 seconds, but I got the jobs done.

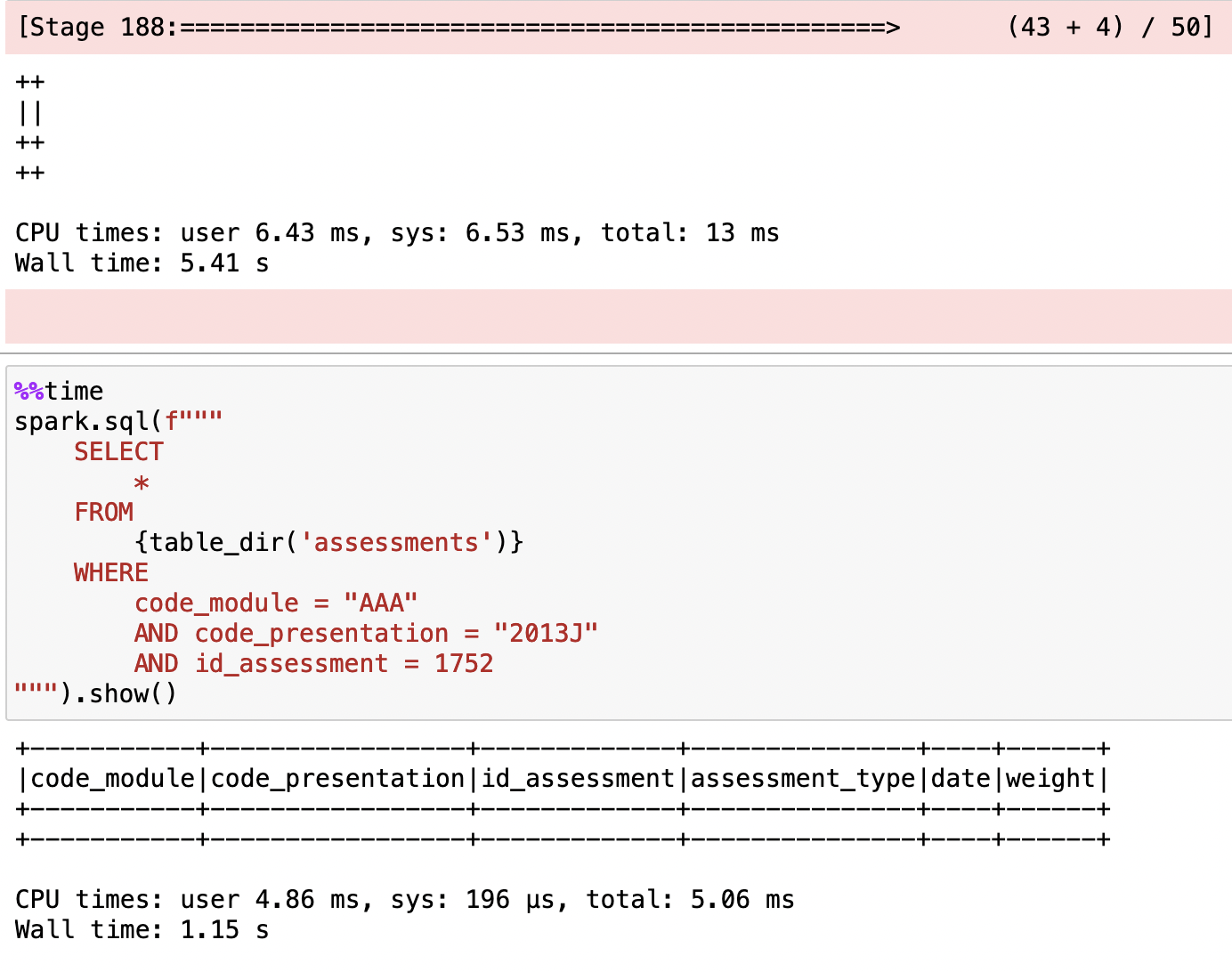
DELETE
Enough with the read. How about writes? Okay, let's try delete first.
spark.sql(f"""
DELETE FROM
{table_dir('assessments')}
WHERE
code_module = "AAA"
AND code_presentation = "2013J"
AND id_assessment = 1752
""").show()
And yes, we can delete stuff.
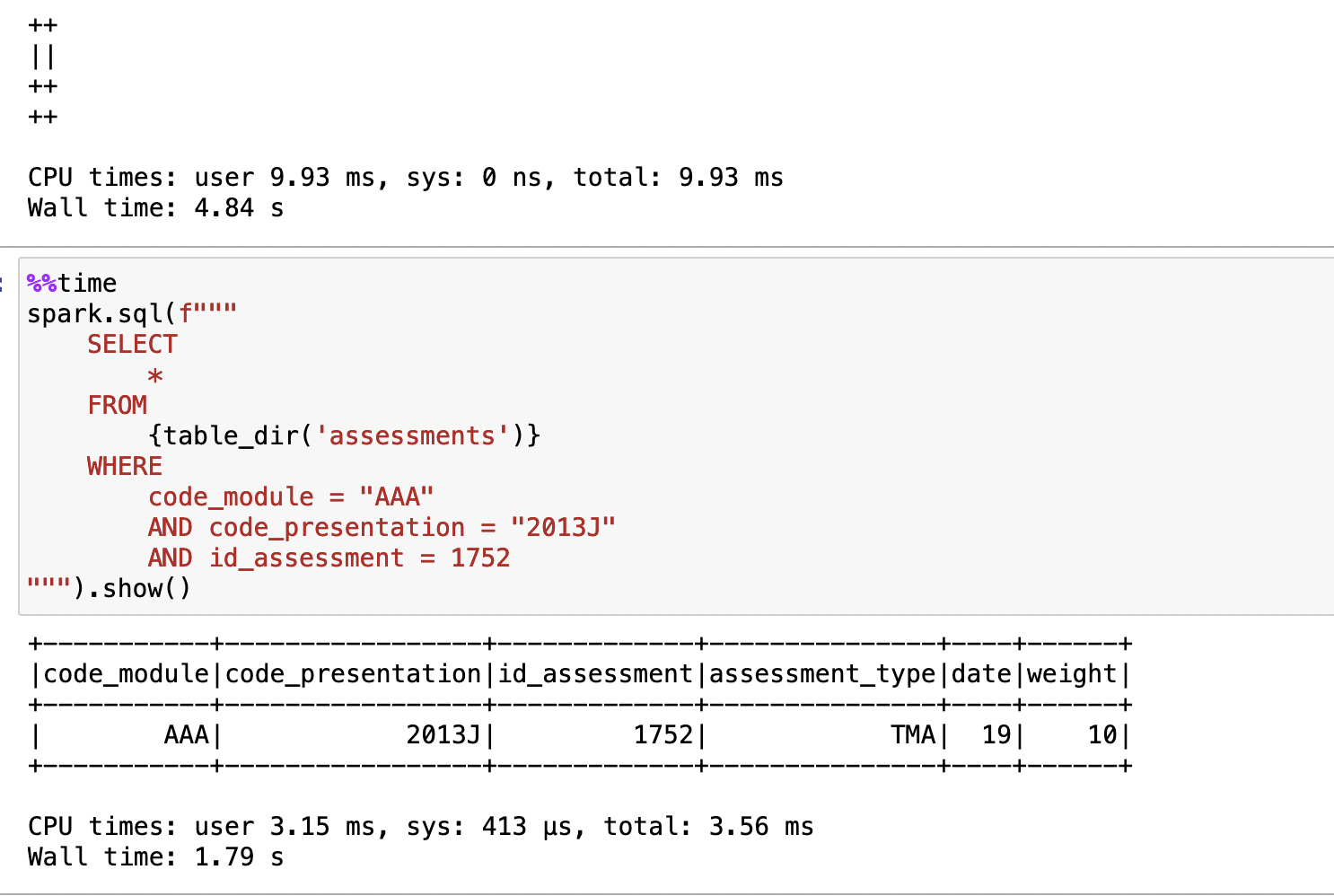
INSERT
Insert it back.
spark.sql(f"""
INSERT INTO
{table_dir('assessments', False)}
VALUES
("AAA","2013J","1752","TMA","19","10")
""").show()
We also can insert stuff.
Closing
With this experiment, we know we can use Delta Lake to import and query data with our beloved SQL. It is good to note that what we do today can be done with normal Apache Spark. Next time, we will do an experiment covering Delta Lake features that made it special. Thank you for reading!